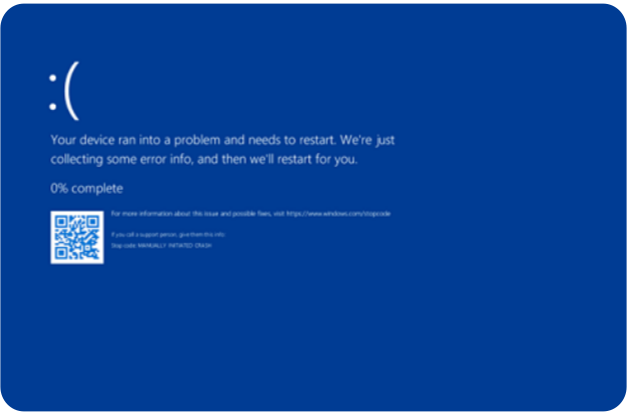
7월 18일, 마이크로소프트(MS) 윈도우를 사용하는 서비스가 전 세계적으로 무한 재부팅되는 장애가 발생하였습니다. 이로 인해 항공사, 금융, 의료 등 다양한 분야에서 시스템이 마비되었으며, 일부 항공사는 수기로 항공권을 발급하고 방송사에서는 방송 송출이 중단되는 사태가 벌어졌습니다.
처음에는 마이크로소프트나 외국 CSP 클라우드의 문제로 보도되었으나, 실제 원인은 타사 보안 솔루션에 있었습니다. 이번 문제는 CrowdStrike의 Falcon 서비스 업데이트 오류로 인해 발생했습니다. 해당 업데이트는 자동 배포 설정이 되어 있어, 인터넷에 연결된 모든 기기에 동시에 영향을 미쳤습니다.
장애 원인
문제의 원인은 미국 보안 업체 CrowdStrike의 Falcon 서비스 업데이트 파일(패치) 오류였습니다. 자동 업데이트가 설정된 시스템이 이 패치를 받으면서 문제가 발생했습니다. CrowdStrike는 78분 만에 수정 패치를 배포했으나, 이미 많은 시스템이 영향을 받아 수작업으로 오류 파일을 삭제해야 했습니다.
사진 출처: Microsoft
대처법
장애 발생 시 대처법 및 권고사항
대처법
만약 문제가 발생했을 경우, 문제가 발생한 윈도우 인스턴스를 재부팅하여 정상 작동 여부를 확인해 주세요. 재부팅 후에도 문제가 해결되지 않으면, 안전모드(AWS 사용자 경우 - EC2 직렬 콘솔)를 실행해 보세요. 안전모드 상태에서 KISA에서 공지한 긴급조치 권고 사항을 참고하여 조치를 시행하시면 됩니다. 자세한 방법은 아래 링크를 참고 부탁드립니다.
크라우드스트라이크 장애 발생 후 보안 및 기업 담당자들에게 크라우드스트라이크 관련 피싱메일이 발송되고 있으므로 주의하시길 바랍니다.
지속적인 인스턴스 백업 계획을 수립하고 시행하는 것이 중요합니다.
OS에 영향을 미칠 수 있는 높은 권한의 솔루션 패치는 스테이징 인프라에서 테스트한 후 운영 환경에 업데이트해 주세요.
서비스 이중화 및 재해 복구(DR) 구성 강화 해주세요.
NDS 권장 사항
지속적이고 안정적인 서비스를 운영하기 위해서 클라우드의 다중 가용 영역에 서비스를 이중화구성하고 가용 영역별로 시차를 두어 배포하는 점진적배포 전략의 적용이 필요합니다.
크라우드스트라이크와 같이 OS에 직접적인 영향을 줄 수 있는 패치 및 업데이트 작업은사전에 테스트 환경에서 정상 동작 테스트를 통해 검증된 패치만 운영 환경에 적용하는 것을 권장합니다.
NDS 제공 서비스
고객 환경 장애에 대한 신속한 대응을 위해 서비스데스크를 운영 중이며, 24시간 관제 모니터링을 제공합니다.
24시간 클라우드 전문가들이 상시 대기중이며 핫라인을 통한 빠른 조치를 제공하여 고객 클라우드 환경의 장애 시간을 최소화할 수 있습니다.
예상치 못한 시스템 오류나 재난 상황에서도 복구가 용이해 IT 사고를 예방할 수 있습니다. 그러나 클라우드 환경에서는 데이터 불일치 등의 문제가 발생할 수 있기 때문에, 전문 MSP의 설계와 관리가 필수적입니다.
저희는 재해 복구를 위한 이중화부터 재난 상황 시 대응 방안까지 기업의 클라우드 운영 전반에 걸쳐 도움을 드리고 있습니다. 이번 IT 블랙아웃 사건을 계기로 클라우드 운영 방식을 재검토하고, MSP의 전문성을 활용하여 더욱 안전하고 안정적인 클라우드 환경을 구축하시기를 바랍니다.
이번 장애로 인해 불편을 겪으신 분들의 신속한 서비스 정상화를 바라며 , 앞으로도 엔디에스는 더 나은 서비스를 제공하기 위해 최선을 다하겠습니다 .